引用是Perl的复杂的数据结构、面向对象编程还有花哨的子程序的基石。它们是在Perl4还有Perl5这段时间被添加进去的。
一个Perl的标量变量存有一个单一的值。一个数组存有一个或者多个标量的有序列表。一个哈希存有一组标量作为值, 然后以另外一组值作为键。尽管一个标量可以是一个任意的字符串,那样就允许复杂的数据被嵌入到数组或者哈希里面去,但是上面的三种数据类型没有一种是很合适复杂的数据间的相互关系的。这就是引用的活了。让我们以一个例子开头看下引用的重要性。
在许多数组上面执行同样的任务
在Minnow开始一个短途旅途的(例如,一个3小时的观光), 我们应该检查每一个乘客还有全体乘务人员来确保他们都拥有必备的旅行用品。比如说, 为了还上航行的安全,Minnow穿上的每个人都得有个救生圈,一些遮光剂,一个水壶还有一个雨衣。我们可以写一些代码来检查Skipper的储备。
1 2 3 4 5 6 7 | |
grep在标量上下文中返回表达式 $item eq $_ 返回 true 的次数,当这件东西在清单里的时候就是1,不在的话就是0. 如果值是0的话,就是假,这个时候我们就把信息给打印出来。
当然如果我们想要检查Gilligan还有Professor的话,我们可能会写如下的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
你可能开始注意到这里有很多的冗余的代码,并且想到我们应该把它重构到一个可以重用的通用的子程序中(你是正确的):
1 2 3 4 5 6 7 8 9 10 11 12 | |
Perl一开始通过它的@_数组给了子程序5个条款:名字gilligan还有属于Gilligan的4个东西。在shift操作之后,@_就只有4个东西了。因此grep通过和清单比对来检查每个所必备的东西。
到目前为止,一切都很好。我们可以通过一点多余的代码来检查Skipper还有Professor的:
1 2 3 4 | |
对于其他的乘客,我们在需要的地方重复下就行了。尽管这个代码符合一开始的要求,我们有两个问题得处理:
*为了创建@_, Perl把数组的整个内容都拷下下来扫描。对于一个元素的话这没什么问题,但是如果数组很大的话,把数据拷贝然后仅仅就是为了传给子程序的话就显得有点浪费了。
*假如我们想要修改原先的数组来迫使供应清单包括一些必备的东西,因为我们在子程序中有一个副本(传值),对@_做的任何的修改都不会自动地反映到对应的供应清单数组中去。
为了解决一个或者两个问题,我们需要的是引用传递而非值传递。这就是doctor(或者Professor)所要求的。
对一个数组做引用
在反斜线()的很多的其他的意思当中,它还是”对某项东西进行引用”的操作符。当我们把它用在一个数组名的前面的时候,比如, \@skipper, 他的结果就是对那个数组的引用。对数组的引用就像是指针: 它指向数组,但是它不是数组本身。
任何变量适宜地方都是适用于引用。它可以作用于一个数组或者哈希的元素,或者一个普通的标量变量, 像下面这样:
1
| |
引用可以被拷贝:
1
| |
甚至于:
1
| |
我们可以相互交换这3个引用。我们甚至可以说它们是相同的,因为事实上,它们就是相同的东西:
1 2 3 | |
这个等式比较两个引用的数值形式。这里引用的数值形式是@skipper内部数据结构的唯一的内存地址, 它在变量的生命周期里是不会改变的。如果我们使用eq或者print来查看它的字符串形式,我们会得到调试出来的字符串:
1
| |
对于这个数组它也是唯一的,因为它包含了数组的唯一地址的16进制表示。调试出来的字符串同样也表示了这是个数组引用。当然要是我们在我们的代码中看到类似的输出,那就基本上表示了有bug。使用我们代码的用户是对16进制的存储地址块没有兴趣的。
因为我们可以拷贝一个引用,向一个子程序传递一个参数事实上就是拷贝,我们可以使用下面的代码来向子程序中的数组传递一个引用:
1 2 3 4 5 6 7 8 9 | |
现在子程序中的$items是对数组@skipper的一个引用。但是我么怎么能够从一个引用得到我们原先的数组呢? 那当然是我们对引用进行解引用了。
对数组引用进行解引用
如果你看一下@skipper的话,你会发现他包含了两部分:@符号以及数组的名字。类似的, 语法$syntax[1]包含了中间部分的数组名以及在外围部分的一些语法来得到数组的第二个元素(指标值1是第二个元素因为指标值从0开始).
下面有个小的技巧: 我们可以向数组中放置任何一个包含在大括号中的引用,来代替数组名,这样就得到了一个获得原先数组的方法。也就是说,任何我们用skipper来命令数组的地方,我们都可以使用大括号中包含引用的形式.:{$items}。例如, 下面的这两行都表示整个的数组。
1 2 3 | |
而下面的这两行都表示了数组的第二个元素:
1 2 3 | |
通过使用引用过的形式,我们把代码还有获取数组的方法从实际的数组分离开了。让我们看一下这是怎样改变了这个子程序的其余的部分的。
1 2 3 4 5 6 7 8 9 10 | |
我们所做的就是把@_(供应清单的副本)替换成@{$items},一个对原先供应清单的引用的解引用. 现在我们就可以像之前那样,对子程序调用几次了:
1 2 3 4 5 6 | |
在每一种情况下,$items都指向一个不同的数组,所以每次我们调用的时候,同样的代码都指向不同的数组。只是引用的最重要的用法之一: 把代码从它所作用的数据结构上面分离开来,那样我们就可以更方便地重用代码了。
通过引用传递数组解决了我们之前提到的两个问题中的第一个问题. 现在,我们得到了一个指向供应清单的单一的引用引用, 而不是把整个的供应清单都拷贝到@_数组中去.
我们可以把子程序开头的两个shift给去掉吗? 当然, 但是那样会牺牲掉清晰性的.
1 2 3 4 5 6 7 8 9 | |
在@_中仍然有两个元素, 第一个元素是乘客或者乘务人员的名字, 我们将在错误信息中使用到。第二个元素是对正确的供应清单的引用,我们在grep表达式中会使用到.
把括号去掉
绝大多数时候,我们想要解引用的那个引用都是简单的标量变量, 如 @{$items} 或者 ${$items}[1]. 在那些情况下去掉大括号,而毫不含糊地就形成了 @$items或者 $$items[1].
然而, 要是大括号中的值不是一个简单的标量变量的时候, 我们就不可以把括号个去掉了. 例如, 对于来自上个自程序中的重写@{$_[1]}, 我们就不可以把括号给去掉了, 那是对数组的单一元素的访问,不是一个标量。
这个规则也表示了我们将很容易看到”缺失”的括号得放到什么地方去. 当我们看到 $$items[1]这个听讨厌的语法的时候,我们可以知道大括号肯定属于简单的表量变量$items的周围。因此,$items肯定是数组的一个引用.
因此, 上面那个子程序的一个看起来更加舒服的版本就是:
1 2 3 4 5 6 7 8 9 10 | |
唯一的区别就是我们把@$items周围的括号给去掉了.
修改数组
你已经看到了怎样通过一个数组的引用来解决过度的复制的问题. 现在让我们看下怎样修改原先的数组.
对于每一个缺失的供应品,我们把它push到一个数组里面去, 强迫乘客考虑这个条款:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
注意下添加的@missing数组。如果我们在扫描的过程中发现了任何物品缺失了, 我们可以把它push到@missing中去。如果在扫描完了之后这个数组中有东西的话,我们就把它添加到原先的供应清单中去。
关键点就是这个子程序中的最后一行。我们对$items数组引用进行解引用,访问原先的数组,然后把@missing中元素添加进去。要是没有引用传值的话,我们将只能修改数据的一个本地的拷贝,那样将对原先的数组没有任何的影响。
同样的, @items(以及它的更加常见的形式@{$items})可以在双引号引起来的字符串中运作。我们不可以在@和接下来的任何的字符之间包含空格,尽管我们可以在大括号中包含任意数量的空格, 就好像那是正常的Perl代码一样。
嵌套的数据结构
在下面的例子中,数组@_包含了两个元素, 其中之一仍然是数组. 如果我们对一个数组进行引用,而这个数组又包含了一个一个对数组的引用, 那将会怎么样呢? 我们得到的将是一个复杂的数据结构, 这将是非常有用的。
例如, 我们可以先构建一个更大的数据结构,它包含了整个的供应清单, 通过来对数据进行递归,我们将得到Skipper, Gilligan还有Professor的信息:
1 2 3 4 5 6 | |
现在@skipper_with_name就有两个元素了, 第二个元素是数组的引用,同我们之前传递给子程序的是相似的。现在我们把这些都组合起来:
1 2 3 4 5 | |
注意我们只有3个元素,其中的每一个都是一个对一个数组的引用,这个数组有两个元素: 名字还有对应的初始供应列表。图4-1是它的一个图片:
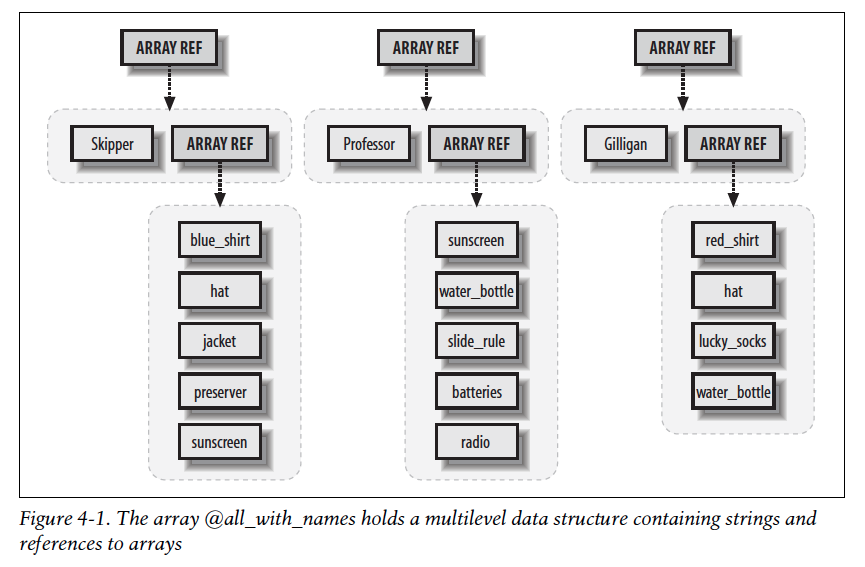
因此,$all_with_names[2]将会是对于Gilligan的数据的数组引用。如果你把它解引用的话@{$all_with_names[2]},你将得到一个两个元素的数组,”Gilligan”还有另一个数组引用。
我们该怎么访问那个数组引用呢? 得再次使用我们的规则了, 也就是${$all_with_names[2]}[1]. 换句话说, 在有了$all_tiwh_names[2]之后, 我们会把它解引用到一个像是普通的数组$DUMMY[1]一样的表达式中去, 所以我们将用{$all_with_names[2]}来替换DUMMY.
我们该如何使用这种数据结构来调用已经存在的 check_required_itesm()例程呢? 下面的代码是足够简单的了:
1 2 3 4 5 | |
这并不要求对子程序做任何的改变。随着循环的推进, 控制变量$person将会依次是$all_with_names[0], $all_with_names[1], $all_with_names[2]中的一个。当我们解引用person[1]是某个人对应的供应清单的数组引用。
当然, 由于整个的被解引用的数组精确地匹配了参数列表,我们也可以把这个过程简化的。
1 2 3 | |
甚至是:
1
| |
正如你所看到的, 多层次的优化会导致困惑的。请确定你考虑到当一个月之后你得再次读你的代码的时候, 你是否能明白。 如果那还不够的话,请考虑下当你离职之后那个接手你的工作的人。
通过箭头来简化嵌套的元素引用
再次看下大括号形式的解引用。正如在我们之前的例子中一样, 对于Gilligan的清单的数组引用是${$all_with_names[2]}[1]. 现在如果我们想知道Gilligan的第一个供应清单该怎么办呢?我们得对这个条款再进一步的解引用, 所以又是另外的一层大括号了: ${${$all_with_names[2]}[1]}[0]. 这真的令人讨厌的语法啊。我们能够简化它吗? 当然可以!
每当我们要写${DUMMY}[$y]的时候,我们可以写DUMMY->[$y]来代替。换句话说,我们可以这样来解引用一个数组的引用, 找出这个数组中的一个特定的元素,这可以简单地通过在定义这个数组的表达式的后面跟上一个箭头还有中括号引起来的下标。
对于这个例子,这意味着我们可以用$all_with_names[2]->[1]来挑出针对Gilligan的数组引用,以及$all_with_names[2]->[1]->[0]来表示Gilligan的第一个物品清单。哇, 那看起来真的舒服多了。
如果那还不够简单的话,还有一条规则可循: 如果箭头处在像方括号这样的可以包含下标的东西之间,我们可以把箭头个去掉。$all_with_names[2]->[1]->[0]就变成了$all_with_names[2][1][0]。 现在看起来就更加地舒服了。
(以下省略一段不翻译了)。
对哈希的引用
正如我们可以对数组进行引用,我们也可以对哈希进行引用。再一次地,我们使用反斜杠来作为引用的操作符.
1 2 3 4 5 6 7 8 | |
我们可以对一个哈希引用进行解引用来得到原先的数据。这个策略同对一个数组引用进行解引用是类似的。
我们像在没有引用的情况下一样写出哈希的语法,然后在包含引用的那个东西的周围使用大括号括起来, 这样子来替换掉原先的哈希名字。例如,为了超出某个键的特定的值,我们可以这样来做:
1 2 | |
在这个例子中,大括号是有着两种不同的意思的. 第一对大括号代表的表达式返回一个引用,而第二个大括号是作为代表哈希键的表达式的界定符.
如同数组的引用一样,我们可以在有些情况下使用快捷方式来替换复杂的大括号的这种形式. 例如, 如果在大括号中只有一个简单的标量变量的话,我们就可以把大括号个去掉的.
1 2 | |
像数组的引用一样, 当指向某个具体的哈希元素的时候,我们可以使用箭头的形式:
1
| |
由于凡是标量变量可以存在的地方, 哈希的引用都可以存在, 所以我们可以创建一个哈希引用的数组,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
因此, $crew[0]是一个指向关于Gilligan的信息的哈希引用。我们可以通过下面的其中之一来得到Gilligan的名字:
1 2 3 4 | |
让我们来打印出一个员工的花名册,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
最后的这部分看起来很冗余,我们可以使用哈希切割来简化它。如果原先的语法是:
1
| |
从引用得来的哈希切割的表示方法如下:
1
| |
我们可以把第一对大括号给去掉,因为里面唯一的东西是一个简单的标量变量值。
1
| |
这样我们就可以把那个最后的循环替换成:
1 2 3 | |
对于数组切割或者哈希切割没有使用箭头形式的简化表示, 正如对于整个的数组后者哈希也没有简化表示一样。